OmniRoute — The Free AI Gateway
Never stop coding. Connect every AI tool to 231 providers — 50+ free — through one endpoint.
Plug Claude Code, Codex, Cursor, Cline, Copilot & Antigravity into FREE Claude / GPT / Gemini. Auto-fallback.
RTK + Caveman compression saves 15–95% tokens. Never hit limits.
~1.6B documented free tokens/month — up to ~2.1B in your first month with signup credits — aggregated across the free tiers, plus a long tail of permanently-free, no-cap providers, and the compression above stretches every one further. (how we count →)
Join the community
Questions, provider tips, roadmap & support → Discord · Telegram · WhatsApp Global / Brasil

![]()






Quick Start • Combos • Providers • CLI & MCP • Compression • Website
The Promise • Why • What Sets Apart • Compatible CLIs • Where It Runs • Private • In Action • Explore More • Support
Stacking free tiers by hand is painful — dozens of SDKs, dozens of rate limits, and no idea how much you actually have. OmniRoute aggregates the documented free tiers of 40+ provider pools / 500+ models into one honest number and shows it live on the dashboard (
/dashboard/free-tiers).
- ~1.6B free tokens / month (steady) — and up to ~2.1B in your first month with signup credits.
- Pool-deduped, honest — we count each shared free pool once, so the headline isn't inflated by rate-limit ceilings the way multi-billion competitor claims are. (Counting every rate limit 24/7 would read ~10B; we don't publish that.)
- Plus the un-countable — permanently-free, no-token-cap providers (SiliconFlow, Z.AI GLM-Flash, Kilo, OpenCode Zen…) and a $10 OpenRouter top-up that unlocks +24M/mo, both surfaced separately so they never inflate the headline.
- Per-model breakdown, live used / remaining for the current month, and a transparent terms flag per provider.

Preview mockup — a real screenshot lands once the
/dashboard/free-tierspage is validated. Full methodology (pool dedupe, credit tiers, provider terms): docs/reference/FREE_TIERS.md.
One endpoint. 231 providers. Never stop building — and let OmniRoute pick the cheapest one that works.
| Never hit limits Auto-fallback across 231 providers in milliseconds. Quota out? Next provider takes over — zero downtime. |
Save up to 95% tokens RTK + Caveman stacked compression cuts 15–95% of eligible tokens (~89% avg on tool-heavy sessions). |
$0 to start 50+ providers with a free tier, 11 free forever (Kiro, Qoder, Pollinations, LongCat…). No card needed. |
| Every tool works 16+ coding agents — Claude Code, Codex, Cursor, Cline, Copilot, Antigravity — through one config. |
One endpoint OpenAI Claude Gemini Responses API translation. Point any tool at /v1 and it just works. |
Production-grade Circuit breakers, TLS stealth, MCP (87 tools), A2A, memory, guardrails, evals. 14,965 tests. |
Stop juggling 10 dashboards, dead API keys, and surprise bills.
| The daily pain | How OmniRoute fixes it |
|---|---|
| Subscription quota expires unused every month | Maximize subscriptions — track quota, use every token before reset |
| Rate limits stop you mid-coding | 4-tier auto-fallback — Subscription → API → Cheap → Free, in milliseconds |
Tool outputs (git diff, grep, logs) burn tokens |
RTK + Caveman compression — save 15–95% eligible tokens per request |
| Expensive APIs ($20–50/mo per provider) | Cost-optimized routing — auto-route to the cheapest viable model |
| Each AI tool wants its own setup | One endpoint, every tool, one dashboard |
| AI blocked in your country | 3-level proxy + TLS fingerprint stealth — use AI from anywhere |
┌──────────────────────────────────────────────────────────┐
│ Your IDE / CLI (Claude Code, Cursor, Cline…) │
└─────────────────────────┬──────────────────────────────────┘
│ http://localhost:20128/v1
▼
┌──────────────────────────────────────────────────────────┐
│ OmniRoute — Smart Router │
│ RTK + Caveman compression · 17 routing strategies │
│ Circuit breakers · TLS stealth · MCP · A2A · Guardrails │
└─────────────────────────┬──────────────────────────────────┘
┌─────────────┬────┴────────┬─────────────┐
▼ Tier 1 ▼ Tier 2 ▼ Tier 3 ▼ Tier 4
SUBSCRIPTION API KEY CHEAP FREE
Claude Code, DeepSeek, GLM $0.5, Kiro, Qoder,
Codex, Copilot Groq, xAI MiniMax $0.2 Pollinations
quota out? ───▶ budget hit? ─▶ budget hit? ─▶ always onA combo is a chain of models OmniRoute routes across automatically. Quota runs out, a provider fails, or costs spike — the combo silently slides to the next model. This is what makes OmniRoute unbreakable.
Zero-config — just use auto
No combo to create. Set your model to auto (or a variant) and OmniRoute builds a virtual combo from your connected providers, scored live:
| Model ID | What it optimizes for |
|---|---|
auto |
Balanced default (LKGP — sticks to your last good provider) |
auto/coding |
Quality-first weights for code generation |
auto/fast |
Lowest latency first |
auto/cheap |
Cheapest per token first |
auto/offline |
Most quota / rate-limit headroom first |
auto/smart |
Quality-first + 10% exploration to discover better models |
Or build your own — 17 routing strategies
| Goal | Strategy / combo |
|---|---|
| Drain my subscription before paying | priority / fill-first |
| Spread load across accounts | round-robin · weighted · p2c · least-used |
| Always cheapest viable model | cost-optimized · auto/cheap |
| Hand off long context between models | context-relay · context-optimized |
| Randomized / privacy routing | random · strict-random |
| Fan out to a panel + judge synthesis | fusion |
| Route by remaining quota headroom | reset-window · headroom |
| Just make it smart | auto (9-factor scoring) · lkgp · reset-aware |
The Auto-Combo engine scores every candidate on 9 factors (health, quota, cost, latency, success rate, freshness…) — see docs/routing/AUTO-COMBO.md.
Resilience is built in (3 independent layers)
| Layer | Scope | What it does |
|---|---|---|
| Circuit breaker | whole provider | Stops hammering a provider that's failing upstream; auto-probes to recover |
| Connection cooldown | one account / key | Skips a rate-limited key while other keys keep serving |
| Model lockout | provider + model | Quarantines just one quota-limited model, not the whole connection |
Combo: "always-on" Strategy: priority
1. cc/claude-opus-4-7 ← subscription (use it fully)
2. cx/gpt-5.5 ← second subscription
3. glm/glm-5.1 ← cheap backup ($0.5/1M)
4. kr/claude-sonnet-4.5 ← FREE, unlimited (never fails)
Result: 4 layers of fallback = zero downtimeAuto-Combo Engine · Resilience Guide
| Feature | OmniRoute | Other routers |
|---|---|---|
| Providers | 231 | 20–100 |
| Free providers | 50+ (11 free forever) | 1–5 |
| Routing strategies | 17 (priority, weighted, cost-optimized, context-relay, fusion…) | 1–3 |
| Token compression | RTK + Caveman stacked (15–95%) | None / 20–40% |
| Built-in MCP server | 87 tools, 3 transports, 30 scopes | Rare |
| A2A agent protocol | 6 skills, JSON-RPC 2.0 | None |
| Memory (FTS5 + vector) | Yes | Rare |
| Guardrails (PII, injection, vision) | Yes | Rare |
| Cloud agents | Codex, Devin, Jules | None |
| TLS fingerprint stealth | JA3/JA4 via wreq-js | None |
| Multi-platform | Web · Desktop · Termux · PWA | Web only |
| i18n | 42 locales | 0–4 |
Detailed comparison vs LiteLLM, OpenRouter & Portkey → docs/comparison/OMNIROUTE_VS_ALTERNATIVES.md
Recent highlights from v3.8.20 → v3.8.38. Full history in
CHANGELOG.md.
- Quota-Share routing — a dedicated combo strategy that spreads load across accounts by available quota: Deficit-Round-Robin scheduling, per-connection
max_concurrentwith cooldown-wait queueing, multi-window usage buckets (5h / 7d / per-model), per-(key,model) caps, session stickiness for prompt-cache integrity, and proactive saturation from upstream token-usage headers. → Resilience Guide - One-command CLI/agent setup — a dedicated
setup-*command configures each coding tool to route through OmniRoute (Claude Code, Codex, Cline, Continue, Cursor, Roo Code, Kilo Code, Crush, Goose, Qwen Code, Aider, OpenCode, Gemini CLI);omniroute launch/omniroute launch-codexare zero-config launchers. → CLI Integrations - Remote mode — drive a remote OmniRoute from any machine with scoped access tokens (
omniroute connect/omniroute contexts/omniroute tokens). → Remote Mode - Smarter auto-routing — OpenRouter-style
auto/<category>:<tier>combos (e.g.auto/coding:fast,auto/reasoning:pro), a Fusion strategy (16th — fan out to a panel of models in parallel, then synthesize via a judge), task-aware routing (best-fit connection per task type), per-requestX-Route-Modeloverride, live Arena-ELO + models.dev model intelligence, per-step account allowlists, provider-wildcard combo steps, nested combo-ref execution, sticky weighted selection, andweb_search-aware routing. → Auto-Combo - Pluggable compression — an async pipeline of 9 composable engines with Compression Studios, an LLMLingua-2 ONNX engine and a heuristic/SLM two-tier Ultra, RTK, delegated Anthropic Context Editing, Output Styles (output-axis steering: terse-prose / less-code / terse-CJK), an adaptive context-budget dial (escalate only as far as needed to fit the context window), per-request
x-omniroute-compressioncontrol, an opt-in offline eval harness, one-click Headroom proxy lifecycle management from the dashboard (Docker sidecar supported), a synthetic compression playground (Play lanes + A/B Compare with USD-capped fidelity verdicts), an opt-in per-step fidelity gate that rejects a lossy engine before it degrades the prompt, and a unified panel with named profiles + an active-profile selector. → Compression - Transparent MITM decrypt (TPROXY) — capture & translate traffic from CLIs that ignore proxy env vars, with a per-SNI certificate authority and a trust-store installer. → MITM/TPROXY
- Cost telemetry everywhere —
X-OmniRoute-*cost/usage headers on every endpoint (including media), a non-token cost engine, a cache-HITX-OmniRoute-Cost-Savedheader, and per-key USD spend quotas. → API Reference - Memory you control — opt-in int8 vector quantization (Qdrant + sqlite-vec), memory off by default, and a per-request
x-omniroute-no-memoryheader. → Memory - Security — a prompt-injection guard across every LLM route (backed by a red-team suite), plus a free DuckDuckGo last-resort web search. → Guardrails
- More providers & agents — Cursor Cloud Agent (a 4th cloud agent), CodeBuddy CN (
copilot.tencent.com), a Google Flow video-generation provider, new gateways DGrid and Pioneer AI (Fastino Labs), inbound xAI Grok translators plus Grok Build (xAI) with an OAuth import-token flow, GPT-4 / GPT-4o-mini on the GitHub Copilot provider, multi-model Factory Droid, ZenMux Free (session-cookie free tier), Alibaba DashScope text-to-video (wan2.7-t2v), a refreshed 231-provider catalog (OrcaRouter, Wafer AI, OpenAdapter, dit.ai, TokenRouter, …), Vertex AI media generation (speech / transcription / music / video), and one-click account import from CLIProxyAPI (~/.cli-proxy-api/). → Providers - Local performance & infra — a one-click local Redis launcher (
omniroute redis up, plus a dashboard Redis panel), one-click Cloudflare Workers and Deno Deploy relay deployers wired into the proxy pool, and an optional Bifrost Go sidecar that offloads the hottest relay path (BIFROST_BASE_URL, with automatic fallback to the TypeScript path on timeout). → Environment
Compatible CLIs & Coding Agents
One config —
http://localhost:20128/v1— and every AI IDE or CLI runs on free & low-cost models.
 Claude Code |
 Codex CLI |
 Gemini CLI |
 Cursor |
 Copilot |
 Continue |
 OpenCode |
 Kilo Code |
 Droid |
 OpenClaw |
 Kiro |
 Command |
Per-tool setup for all 16+ tools → docs/reference/CLI-TOOLS.md · OpenCode plugin → @omniroute/opencode-provider
The most complete catalog of any open-source router: 231 providers, 50+ with a free tier, 11 free forever.
Free Forever — $0, no card
GPT-5, Claude, Gemini $100 free credits |
Kimi-K2, DeepSeek-R1 Unlimited FREE |
GPT-5, Claude, Llama 4 No key needed |
Flash-Lite 50M tokens/day |
50+ models 10K neurons/day |
gemini-3-flash 180K/mo free |
129 models ~40 RPM free |
Qwen3 235B 1M tokens/day |
Full machine-readable catalog → docs/reference/PROVIDER_REFERENCE.md
Same app, your machine, your rules. From a global npm install to your phone via Termux.
| Platform | Install | Highlights |
|---|---|---|
| npm (global) | npm install -g omniroute |
One command, any OS |
| Docker | docker run … diegosouzapw/omniroute |
Multi-arch AMD64 + ARM64 |
| Desktop (Electron) | npm run electron:build |
Native window + system tray — Windows / macOS / Linux |
| ARM | native arm64 |
Raspberry Pi, ARM servers, Apple Silicon |
| Android (Termux) | pkg install nodejs-lts && npx -y omniroute |
Runs on your phone, 24/7, no root |
| PWA | "Add to Home Screen" | Fullscreen, offline, installable from browser |
| OpenCode plugin | @omniroute/opencode-provider |
Native OpenCode integration |
| From source | npm install && npm run dev |
Hack on it, contribute |
Docker Guide · Desktop · Termux · PWA · OpenCode
Your keys, your machine, your data. OmniRoute is a local proxy — it never phones home.
- Runs 100% on your hardware — npm, Docker, desktop, or your phone. No OmniRoute cloud sits in the request path.
- Credentials encrypted at rest — API keys & OAuth tokens sealed with AES-256-GCM.
- Zero telemetry by default — your prompts go only to the providers you choose, nowhere else.
- Hardened gateway — API-key scoping, IP filtering, rate limits, prompt-injection guard, loopback-only process routes.
- MIT licensed & fully open-source — audit every line, self-host forever.
Authorization · Guardrails · Compliance
OmniRoute isn't just a server — it's a full command-line cockpit with 60+ commands, plus open agent protocols so an AI agent can drive OmniRoute by itself.
A real CLI (not just start)
omniroute # serve gateway + dashboard (port 20128)
omniroute chat # interactive TUI chat client (slash: /model /combo /skill /memory)
omniroute setup # guided first-run wizard
omniroute doctor # diagnose providers, ports, native depsRemote mode — run the CLI here, OmniRoute on a VPS
OmniRoute on a server? Drive it from your laptop with the same CLI. Log in once with a scoped access token; every command then targets the remote.
omniroute connect 192.168.0.15 # password → scoped token, saved as a context
omniroute models list # ← runs against the REMOTE server
omniroute configure codex # ← picks a remote model, writes a local Codex profile
omniroute tokens create --name ci --scope read # mint narrower tokens for other machines
omniroute contexts use default # ← switch back to the local serverTokens are scoped read / write / admin; process-spawning routes stay loopback-only.
Remote Mode
providers · oauth · keys · combo · nodes · models · cache · compression · cost · usage · quota · health · resilience · telemetry · logs · audit · mcp · a2a · cloud · memory · skills · eval · tunnel · backup · sync · webhooks · policy · pricing · translator · simulate …
Connect an agent — and it controls OmniRoute itself
Expose OmniRoute over MCP or A2A and any capable agent gets the keys to the whole gateway — routing, providers, combos, cache, compression, memory — autonomously.
| Protocol | Endpoint | Use it for |
|---|---|---|
| MCP (stdio) | omniroute --mcp |
Plug into Claude Desktop, Cursor, any MCP client |
| MCP (HTTP) | http://localhost:20128/api/mcp/stream |
Remote MCP — 87 tools, 30 scopes, full audit trail |
| MCP (SSE) | http://localhost:20128/api/mcp/sse |
Streaming MCP transport |
| A2A | http://localhost:20128/.well-known/agent.json |
Agent-to-agent, JSON-RPC 2.0 + SSE, 6 skills |
# Give Claude Code the full OmniRoute toolset over MCP:
claude mcp add-server omniroute --type http --url http://localhost:20128/api/mcp/streamMCP Server · A2A Server · Agent Protocols
Why use many token when few token do trick? Every request passes through OmniRoute's compression pipeline transparently — no client changes. It's now a stack of 9 composable engines that run in order and mix & match per routing combo — building on ideas from RTK, Caveman ( 51K+), LLMLingua-2, and Troglodita (PT-BR).
The 9-engine stack
Engines run in pipeline order; each is independently toggleable and configurable per combo:
| # | Engine | What it does |
|---|---|---|
| 1 | Session-Dedup | Drops content repeated across turns (content-addressed, cross-turn) |
| 2 | CCR | Archives large blocks behind retrieve markers, fetched on demand |
| 3 | RTK | Smart tool-result filtering, dedup & truncation (command-aware) |
| 4 | Headroom | Lossless tabular compaction of homogeneous JSON arrays (~30%+) |
| 5 | Caveman | Rule-based prose compression (~65–75% on output) |
| 6 | LLMLingua-2 | ML semantic pruning via MobileBERT ONNX — code-safe, async |
| 7 | Lite | Whitespace + image-URL trimming (latency-light baseline) |
| 8 | Aggressive | Summarization + progressive aging of old turns |
| 9 | Ultra | Heuristic token pruning with an optional small-model (SLM) tier |
Code blocks, URLs and structured data are always preserved byte-perfect. One-click presets combine the engines:
| Mode | Savings | Best for |
|---|---|---|
| Lite | ~15% | Always-on safe default |
| Standard (Caveman) | ~30% | Daily coding |
| Aggressive | ~50% | Long tool-heavy sessions |
| Ultra | ~75% | Maximum savings |
| RTK | 60–90% | Shell/test/build/git output |
| Stacked (RTK → Caveman) | 78–95% | Mixed prompts + tool logs |
Real example — Standard mode:
Before (69 tokens): "The reason your React component is re-rendering is likely because you're creating a new object reference on each render cycle. When you pass an inline object as a prop, React's shallow comparison sees it as a different object every time, which triggers a re-render. I would recommend using useMemo to memoize the object."
After (19 tokens): "New object ref each render. Inline object prop = new ref = re-render. Wrap in useMemo."
Same answer. 72% fewer tokens. Zero accuracy loss.
PT-BR example — Troglodita mode:
Antes (42 tokens): "O problema é que o componente está re-renderizando porque uma nova referência de objeto está sendo criada em cada ciclo de renderização. Eu recomendaria usar useMemo."
Depois (12 tokens): "Re-render: ref nova cada ciclo (objeto inline recriado). Usar
useMemo."Mesma resposta. ~70% menos tokens. Precisão técnica intacta.
How it works — pipeline, architecture & savings math
Client (10,000 tok) ──▶ OmniRoute Compression (9 engines) ──▶ Provider (~1,080 tok, up to 95% saved)Default stacked combo runs RTK → Caveman. When both act on the same tool/context payload, savings compound:
combined = 1 − (1 − RTK) × (1 − Caveman_input)
average = 1 − (1 − 0.80) × (1 − 0.46) = 89.2%
range = 78.4 – 94.6%Code blocks, URLs, JSON and structured data are always protected by the preservation engine.
Beyond the engines — output styles, the adaptive dial & per-request control
The 9 engines above shrink what goes in. Three more layers shape how, when, and what comes out:
- Output Styles (output-axis steering) — inject deterministic, cache-safe response-shaping instructions; combinable, each at
lite/full/ultraintensity. Adding a style is a one-line registry entry:- Terse prose — drop filler / articles / hedging; keep technical substance exact.
- Less code — "lazy senior dev" YAGNI: smallest working change, no unrequested scaffolding.
- Terse CJK (文言) — classical-Chinese ultra-terse style (locale-gated to
zh).
- Adaptive context-budget (the dial) — instead of one on/off token threshold, escalate the cheapest, most-lossless engines only as far as needed to fit the model's context window. Policy:
reserve-output(default, model-aware) ·percentage·absolute. Mode:floor(guarantee fit) ·replace-autotrigger(your explicit choice wins) ·off(legacy threshold). - Where compression is decided (precedence, high → low) — per-request
x-omniroute-compressionheader › routing-combo override › active named profile › adaptive / auto-trigger › panel default › off. The applied plan echoes back in theX-OmniRoute-Compression: <mode>; source=<source>response header.
Auto-trigger by token threshold, flip on the adaptive dial, pin a named profile, set a one-off per request, or assign a pipeline per routing combo — whichever fits the workload. An opt-in offline eval harness (npm run eval:compression) scores fidelity vs. savings on a pinned corpus before you promote a change.
COMPRESSION_GUIDE.md · RTK_COMPRESSION.md · COMPRESSION_ENGINES.md
1) Install & run
npm install -g omniroute
omnirouteDashboard at http://localhost:20128 · API at http://localhost:20128/v1.
2) Connect a FREE provider (no signup)
Dashboard → Providers → connect Kiro AI (free Claude, ~50 credits/month per account) or OpenCode Free (no auth) → done.
3) Point your coding tool
Base URL: http://localhost:20128/v1
API Key: [copy from Dashboard → Endpoints]
Model: auto (zero-config smart routing — or any provider/model)4) Verify it's working
curl http://localhost:20128/v1/models -H "Authorization: Bearer YOUR_KEY"You should see your connected models listed. That's it — start coding, and OmniRoute auto-routes & falls back for you.
If your client cannot send custom headers, OmniRoute also exposes tokenized compatibility aliases:
OpenAI catalog: http://localhost:20128/vscode/YOUR_KEY/
OpenAI models: http://localhost:20128/vscode/YOUR_KEY/models
OpenAI chat: http://localhost:20128/vscode/YOUR_KEY/chat/completions
OpenAI responses: http://localhost:20128/vscode/YOUR_KEY/responses
Ollama chat: http://localhost:20128/vscode/YOUR_KEY/api/chat
Ollama tags: http://localhost:20128/vscode/YOUR_KEY/api/tagsUse these only for clients that cannot attach Authorization: Bearer .... Header auth remains the preferred mode.
More install methods — Docker, source, pnpm, Arch
Docker
docker run -d --name omniroute --restart unless-stopped --stop-timeout 40 \
-p 20128:20128 -v omniroute-data:/app/data diegosouzapw/omniroute:latestFrom source
cp .env.example .env && npm install
PORT=20128 npm run devpnpm
pnpm install -g omniroute && pnpm approve-builds -g && omnirouteArch Linux (AUR)
yay -S omniroute-bin && systemctl --user enable --now omniroute.serviceNix (Flake)
# Using Nix flakes
nix develop
npm run dev
# Or using devbox
devbox run npm run devDocker Guide — Compose profiles, Caddy HTTPS, Cloudflare tunnels.
Podman
# 1. Build the image
podman build --target runner-base -t omniroute:base .
# 2. Fix data directory permissions for rootless Podman
mkdir -p data && podman unshare chown 1000:1000 ./data
# 3. Set runtime in .env, then run (see contrib/podman/ for Quadlet)
echo "CONTAINER_HOST=podman" >> .env
podman compose --profile base up -dPodman Guide — Quadlet setup, podman-compose, Quadlet.
 Português Guia completo |
 English Complete walkthrough |
 Русский Полное руководство |
Made a video about OmniRoute? Open an issue or discussion with the link — we'll feature it here.
Pricing at a glance & the $0 Free Stack (11 providers)
| Tier | Example | Cost |
|---|---|---|
| Subscription | Claude Code Pro / Codex / Copilot | $10–200/mo |
| API Key (free tiers) | NVIDIA NIM, Cerebras, Groq | FREE |
| Cheap | GLM-5 $0.5/1M · MiniMax M2.5 $0.3/1M | pennies |
| Free Forever | Kiro, Qoder, Qwen, Pollinations, LongCat | $0 |
The $0 Free Stack — combine into one unbreakable combo:
| Provider | Prefix | Free models | Quota |
|---|---|---|---|
| Kiro | kr/ |
Claude Sonnet 4.5, Haiku 4.5, Opus 4.6 | 50 credits/mo |
| Qoder | if/ |
kimi-k2-thinking, qwen3-coder-plus, deepseek-r1 | Unlimited |
| Qwen | qw/ |
qwen3-coder-plus/flash/next | Unlimited |
| Pollinations | pol/ |
GPT-5, Claude, Gemini, DeepSeek, Llama 4 | No key needed |
| LongCat | lc/ |
LongCat-Flash-Lite | 50M tokens/day |
| Cloudflare AI | cf/ |
50+ models | 10K neurons/day |
| NVIDIA NIM | nvidia/ |
129 models | ~40 RPM |
| Cerebras | cerebras/ |
Qwen3 235B, GPT-OSS 120B | 1M tok/day |
The dashboard "cost" is a savings tracker, not a bill — OmniRoute never charges you. A "$290 total cost" using free models means $290 saved.
Complete free directory → docs/reference/FREE_TIERS.md — 25+ providers, quotas, base URLs.
Use Cases — ready-made combo playbooks
$0 forever:
1. kr/claude-sonnet-4.5 (Kiro — ~50 credits/mo per acct)
2. if/kimi-k2-thinking (Qoder — unlimited)
3. pol/gpt-5 (Pollinations — no key)
4. lc/longcat-flash-lite (50M tok/day backup)
Compression: aggressive (~50%) → double your free quota · Cost: $0/mo24/7 no interruptions: chain 2 subscriptions → cheap → free for 5 layers of fallback.
Blocked region: free providers + global/per-provider proxy → access AI from any country.
Max savings: subscription + cheap backup + ultra compression (~75%) → ~$150–300/mo saved for heavy users.
Bypass geo-blocks — 3-level proxy + stealth
In a blocked region? OmniRoute's 3-level proxy (Global / Per-Provider / Per-Connection) proxies API requests, OAuth flows, connection tests, token refresh & model sync.
- Protocols: HTTP/HTTPS, SOCKS5, authenticated proxies
- 1proxy marketplace — hundreds of free validated proxies, quality scores, auto-rotation
- Anti-detection — TLS fingerprint spoofing (
wreq-js), CLI fingerprint matching, proxy IP preservation
Full feature list — 30+ capabilities (memory, evals, observability)
Routing: 15 strategies · task-aware smart routing · thinking budget controls · wildcard routing · system prompt injection.
Compatibility: OpenAI Claude Gemini Responses API · auto OAuth refresh (PKCE, 8 providers) · multi-account round-robin · Batch + Files API · live OpenAPI 3.0.
Protocols: MCP (87 tools, 3 transports, 30 scopes) · A2A (JSON-RPC 2.0, SSE, 6 skills) · ACP · cloud agents (Codex, Devin, Jules).
Plugins: custom plugin marketplace (system-configured registry URL with SSRF-guarded fetch) · install / enable / disable · Notion + Obsidian knowledge-base integrations (WebDAV file server, vault search, note CRUD).
Embedded services: one-click install & lifecycle management of local sidecar services (CLIProxy, NineRouter).
Quality & Ops: built-in Evals (golden-set: exact/contains/regex/custom) · guardrails (PII, injection, vision) · health dashboard · p50/p95/p99 telemetry · webhooks · compliance audit.
AI Agent Skills: drop-in markdown manifests — point any agent at a skills/*/SKILL.md manifest. 43 skills available.
MCP Server · A2A Server · Resilience Guide · Features Gallery
Setup, env vars & FAQ
| Env var | Default | Purpose |
|---|---|---|
PORT |
20128 |
API + dashboard port |
REQUIRE_API_KEY |
false |
Require API key for all requests |
DATA_DIR |
~/.omniroute |
Database & config storage |
Will I be charged by OmniRoute? No — it's free, open-source software on your machine. You only pay paid providers directly. OmniRoute has no billing system. Are FREE providers really unlimited? Mostly — Qoder, Pollinations, LongCat, and Cloudflare are free with no per-account credit cap. Kiro is free too but capped at ~50 credits/month per account. Stack multiple free providers in a combo and auto-fallback keeps you serving for $0. Will compression hurt quality? No — it only compresses the input; code, URLs, JSON are always protected. Does it work where AI is blocked? Yes — 3-level proxy + 1proxy marketplace reach all 231 providers.
Troubleshooting
| Problem | Quick fix |
|---|---|
| "Language model did not provide messages" | Provider quota exhausted → use a combo fallback |
| Rate limiting (429) | Add fallback: cc/claude → glm/glm-4.7 → if/kimi-k2-thinking |
| OAuth token expired | Auto-refreshed; if stuck, delete + re-auth in Providers |
unsupported_country_region_territory |
Configure proxy in Settings → Proxy |
| Docker SQLite locks | Use --stop-timeout 40 for clean WAL checkpoint |
| Node runtime errors | Use Node >=22.0.0 <23 or >=24.0.0 <27 |
Reporting a bug? Run npm run system-info and attach system-info.txt. docs/guides/TROUBLESHOOTING.md
Dashboard screenshots
| Page | Screenshot | Page | Screenshot |
|---|---|---|---|
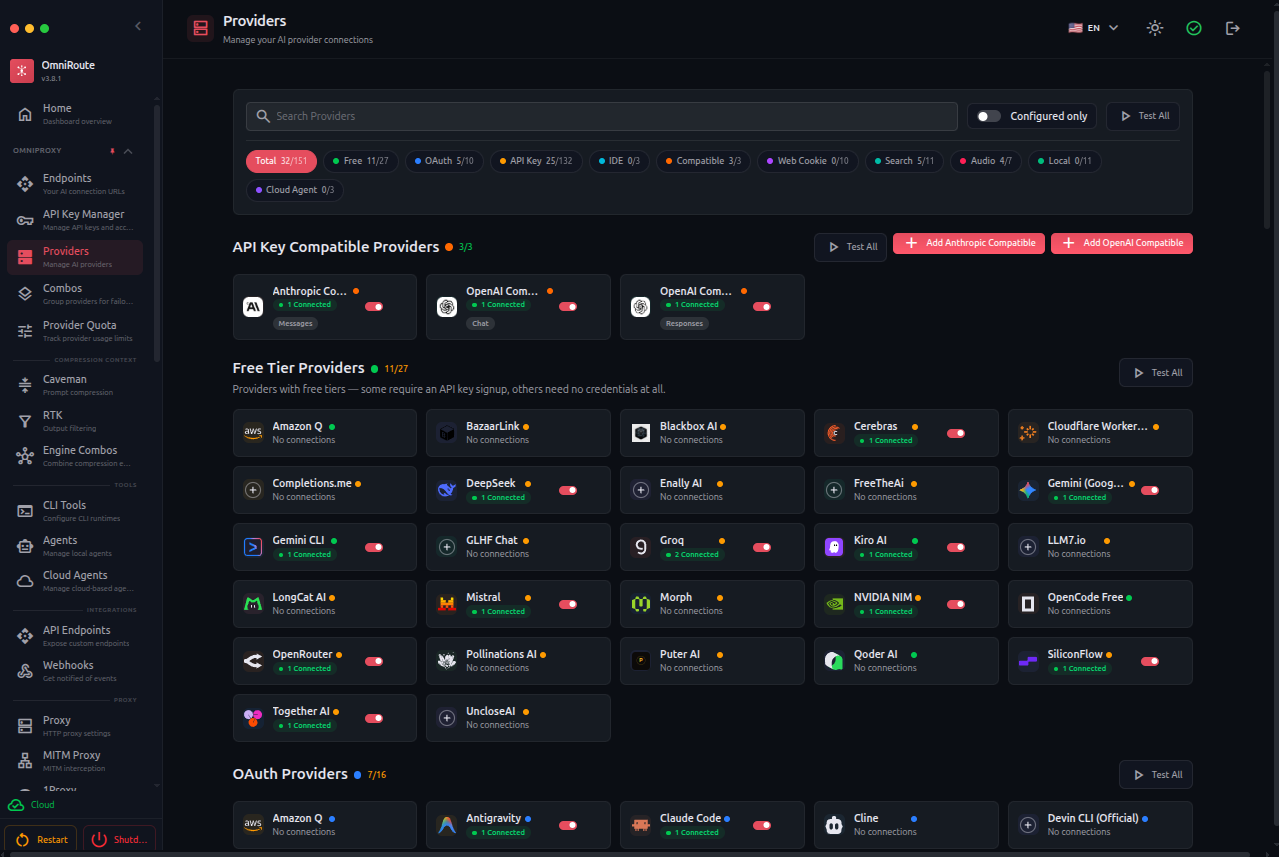
| Providers | 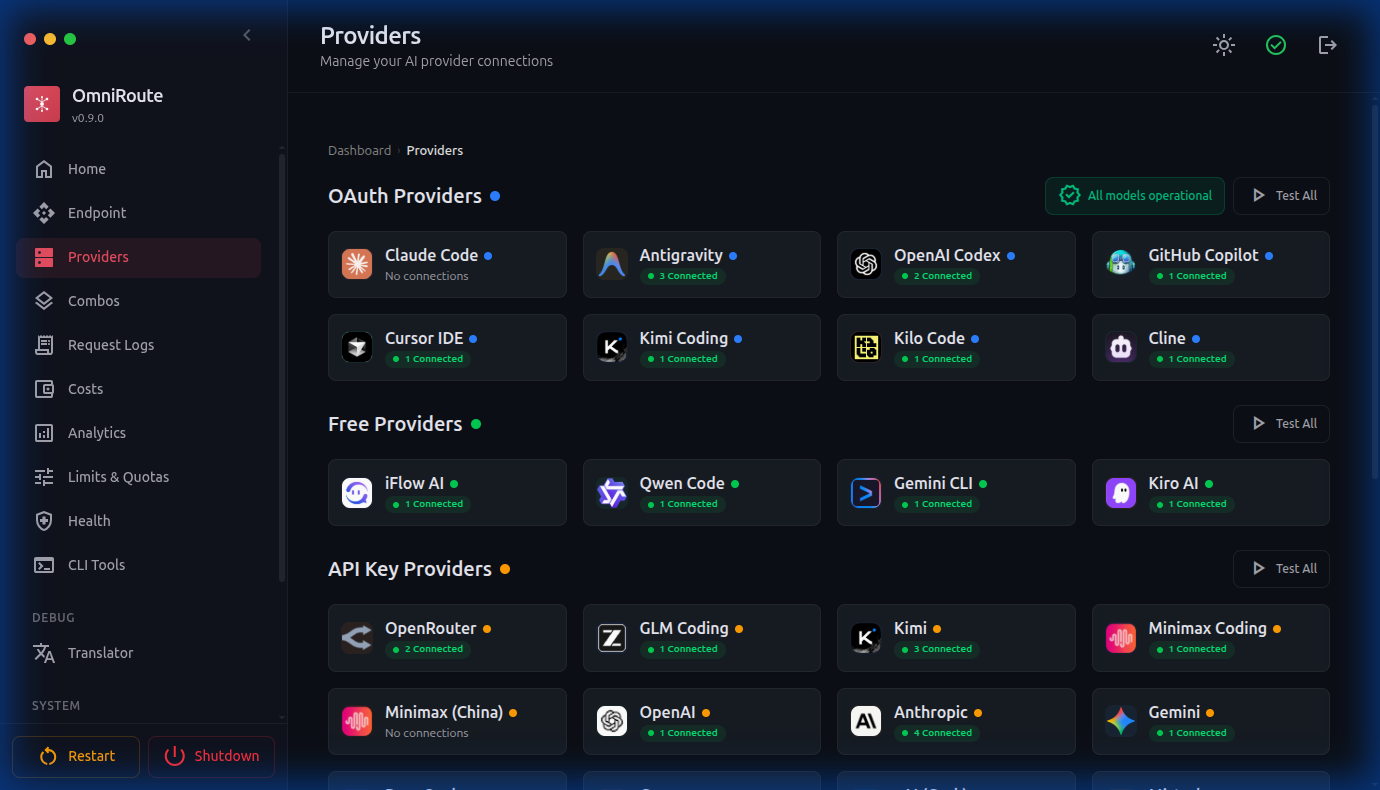 |
Combos | 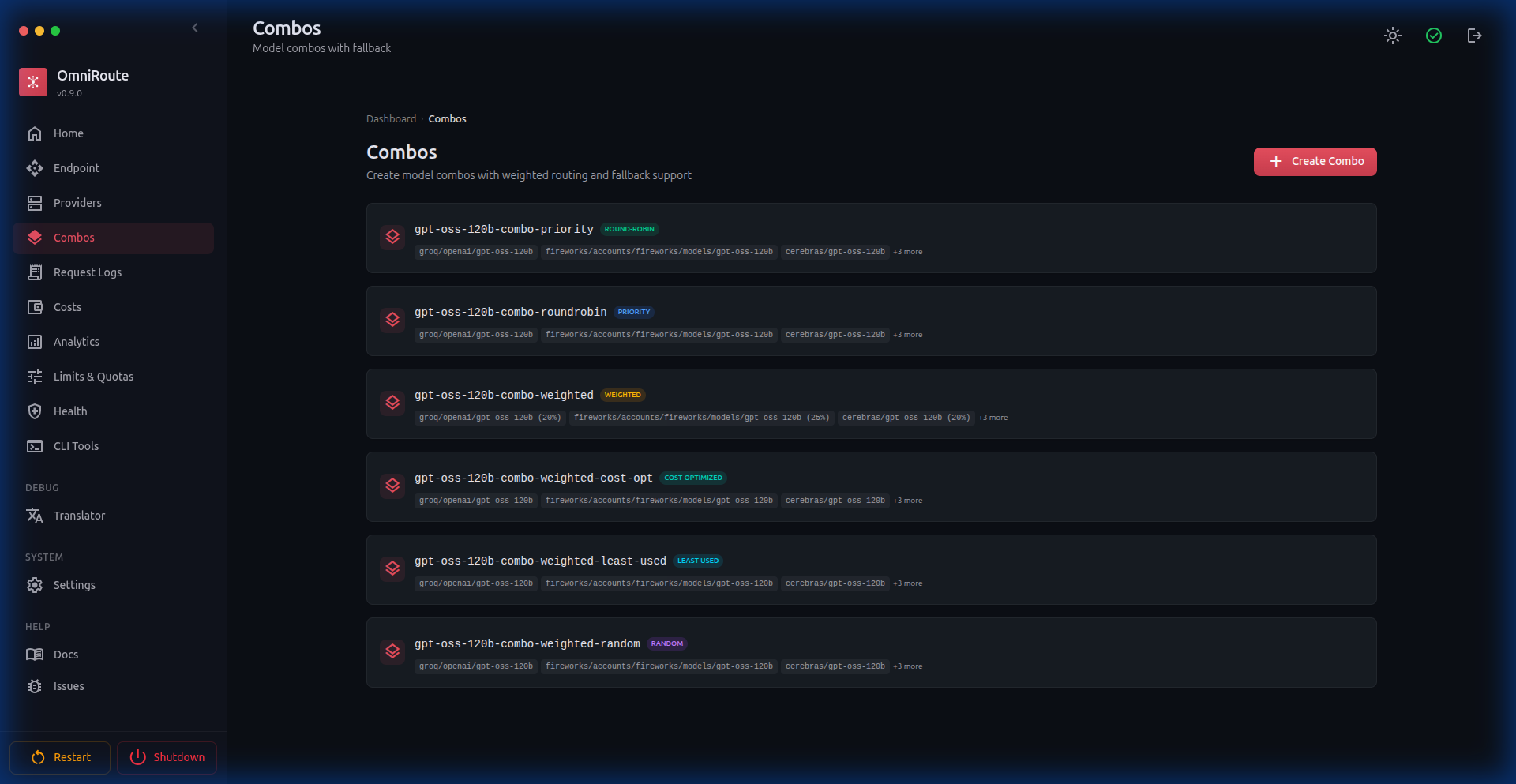 |
| Analytics | 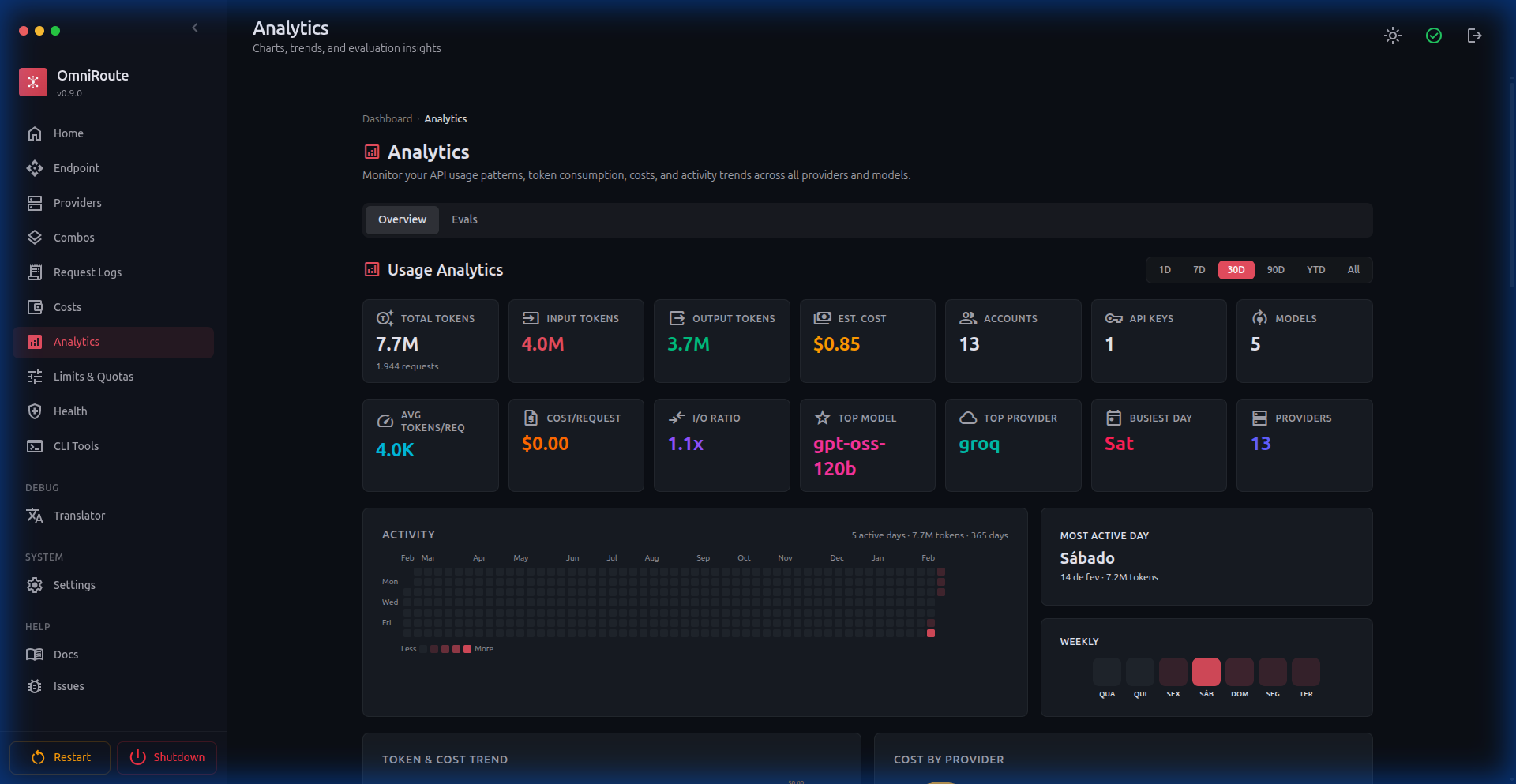 |
Health |  |
| Translator |  |
Settings |  |
| CLI Tools |  |
Usage Logs | 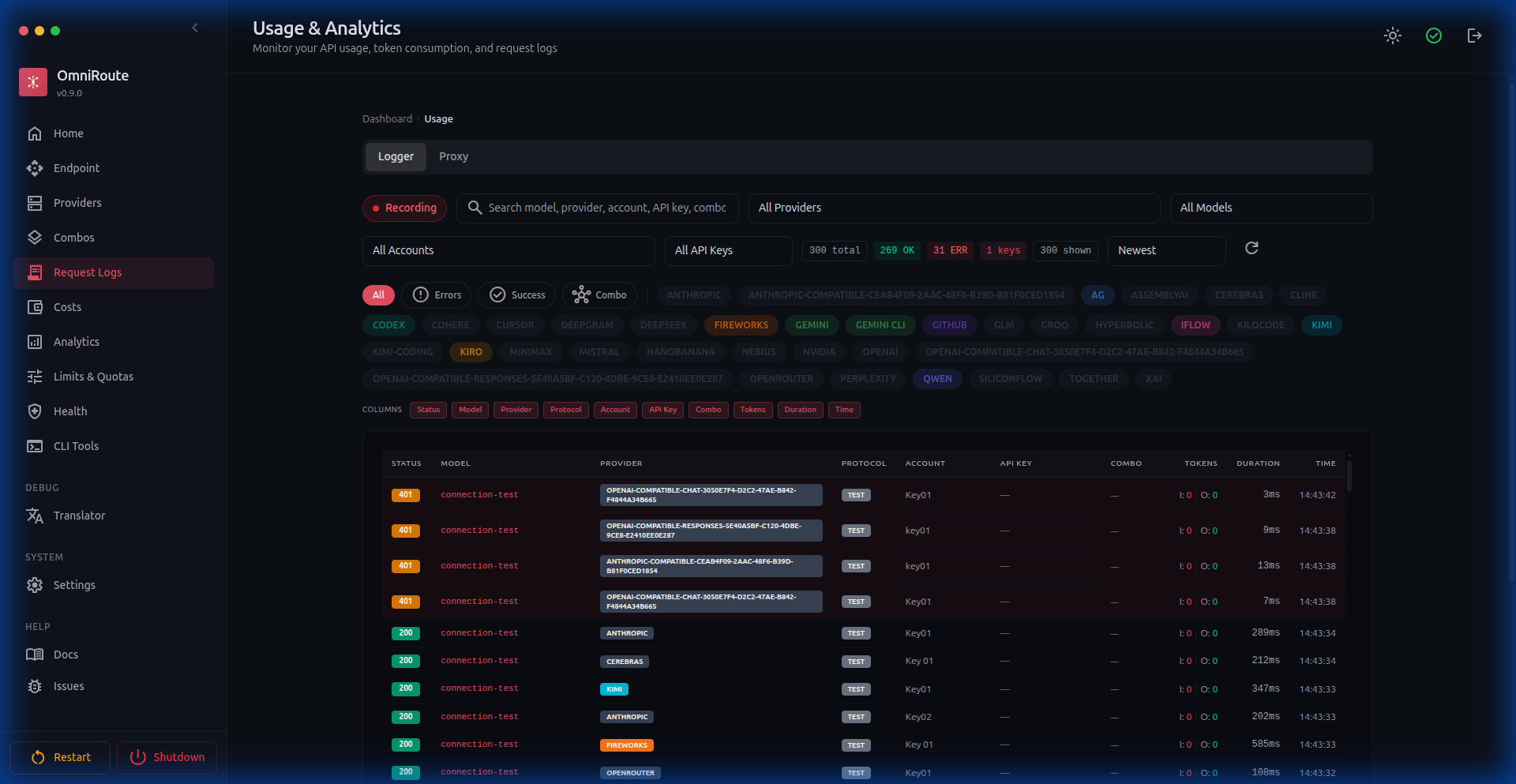 |
Support & Community
Chat with the community — Discord, Telegram & WhatsApp ( / ) links are at the top of this README.
- Website: omniroute.online
- GitHub: github.com/diegosouzapw/OmniRoute
- Issues: report a bug (attach
npm run system-infooutput) - Contributing: see CONTRIBUTING.md or pick a
good first issue
- Runtime: Node.js 22.x or 24.x LTS (24 LTS recommended) —
>=22.0.0 <23 || >=24.0.0 <27 - Language: TypeScript 6.0 — 100% TypeScript across
src/andopen-sse/(zeroanyin core modules since v2.0) - Framework: Next.js 16 + React 19 + Tailwind CSS 4
- Database: better-sqlite3 (SQLite) + LowDB (JSON legacy) — domain state, proxy logs, MCP audit, routing decisions, memory, skills
- Schemas: Zod (MCP tool I/O validation, API contracts)
- Protocols: MCP (stdio/HTTP) + A2A v0.3 (JSON-RPC 2.0 + SSE)
- Streaming: Server-Sent Events (SSE) + WebSocket bridge (
/v1/ws) - Auth: OAuth 2.0 (PKCE) + JWT + API Keys + MCP Scoped Authorization
- Testing: Node.js test runner + Vitest (14,965 test cases across 517 files — unit, integration, E2E, security, ecosystem)
- Platforms: Desktop (Electron), Android (Termux), PWA (any browser)
- CI/CD: GitHub Actions (auto npm publish + Docker Hub on release)
- Website: omniroute.online
- Package: npmjs.com/package/omniroute
- Docker: hub.docker.com/r/diegosouzapw/omniroute
- Resilience: Circuit breaker, exponential backoff, anti-thundering herd, TLS spoofing, auto-combo self-healing
Getting Started
| Document | Description |
|---|---|
| User Guide | Providers, combos, CLI integration, deployment |
| Setup Guide | Full install methods, CLI tool configs, protocol setup, timeout tuning |
| CLI Tools Guide | Per-tool setup for Claude Code, Codex, Cursor, Cline, OpenClaw, Kilo, Copilot |
| Remote Mode | Drive a remote OmniRoute (VPS) from your laptop CLI via scoped access tokens |
| Claude Code Config | Point Claude Code at OmniRoute (local/remote) with launch + per-model profiles |
| Quick Start | 3-step install → connect → configure |
Operations & Deployment
| Document | Description |
|---|---|
| Docker Guide | Docker run, Compose profiles, Caddy HTTPS, tunnels, image tags |
| Podman Guide | Quadlet systemd integration, podman-compose, SELinux |
| VM Deployment | Complete guide: VM + nginx + Cloudflare setup |
| Fly.io Deployment | Deploy to Fly.io with persistent storage |
| Termux Guide | Run OmniRoute on Android via Termux |
| PWA Guide | Progressive Web App install, caching, architecture |
| Uninstall Guide | Clean removal for all install methods |
| Environment Config | Complete .env variables and references |
Features & Architecture
| Document | Description |
|---|---|
| Architecture | System architecture, data flow, and internals |
| Compression Guide | 7-option pipeline: off / lite / standard / aggressive / ultra / RTK / stacked |
| RTK Compression | Command-output compression, filters, trust, verify, raw-output recovery |
| Compression Engines | Caveman, RTK, stacked pipelines, dashboard/API/MCP surfaces |
| Compression Rules Format | JSON rule-pack schemas for Caveman and RTK filters |
| Compression Language Packs | Language detection and Caveman rule-pack authoring |
| Resilience Guide | Circuit breakers, cooldowns, queue, anti-thundering herd, TLS spoofing |
| Auto-Combo Engine | 9-factor scoring, mode packs, self-healing |
| Proxy Guide | 3-level proxy system, 1proxy marketplace, registry CRUD |
| Free Tiers | 25+ free API providers consolidated directory |
| Features Gallery | Visual dashboard tour with screenshots |
| Codebase Documentation | Beginner-friendly codebase walkthrough |
Protocols & APIs
| Document | Description |
|---|---|
| API Reference | All endpoints with examples |
| OpenAPI Spec | OpenAPI 3.0 specification |
| MCP Server | 87 MCP tools, IDE configs, Python/TS/Go clients |
| MCP Server Guide | MCP installation, transports, and tool reference |
| A2A Server | JSON-RPC 2.0 protocol, skills, streaming, task mgmt |
| A2A Server Guide | A2A agent card, tasks, skills, and streaming |
Project & Quality
| Document | Description |
|---|---|
| Contributing | Development setup and guidelines |
| Changelog | Full per-version release history |
| Security Policy | Vulnerability reporting and security practices |
| i18n Guide | 40+ language support, translation workflow, RTL |
| Release Checklist | Pre-release validation steps |
| Coverage Plan | Test coverage strategy and 14,965 test suite |
Top Contributors
OmniRoute is shaped by a passionate open-source community. These individuals have made exceptional contributions that directly impact the quality, stability, and reach of the project. Thank you.
 oyi77 190 commits • +72K lines Analytics engine, SQL aggregations, proxy marketplace, test coverage |
 Chris Staley 72 commits • +5.7K lines SSE stream hardening, Responses API, Gemini pagination, test regression fixes |
 zenobit 62 commits • +24K lines CI/CD pipeline, i18n for 33 languages, Void Linux package, platform fixes |
 R.D. & Randi 107 commits • +28K lines Endpoints page, tunnel integrations, Docker workflows, A2A status, compression UI |
 benzntech 20 commits • +7.5K lines Electron desktop app, auto-updater, release build workflows, cross-platform CI |
These contributors' features, bug fixes, and infrastructure improvements are a core part of what makes OmniRoute reliable and feature-rich. Every pull request, every test case, and every i18n translation file matters. Open source is built by people like them.
How to Contribute
- Fork the repository
- Create your feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
See CONTRIBUTING.md for detailed guidelines.
Releasing a New Version
# Create a release — npm publish happens automatically
gh release create v3.8.2 --title "v3.8.2" --generate-notesOmniRoute stands on the shoulders of giants. It started as a fork of 9router and a TypeScript port of the Go project CLIProxyAPI — and from there, every subsystem below was inspired by an open-source project that got there first. Each one shaped a concrete piece of OmniRoute. This is our thank-you to all of them.
star counts as of June 2026 — go give these projects a star.
Lineage & gateway
| Project | How it inspired OmniRoute | |
|---|---|---|
| 9router · decolua | 17.9k | The original project this fork is built on — extended here with multi-modal APIs and a full TypeScript rewrite. |
| CLIProxyAPI · router-for-me | 37.8k | The Go implementation that inspired this JavaScript / TypeScript port. |
| LiteLLM · BerriAI | 50.8k | The AI gateway whose public pricing dataset feeds our cost-tracking sync and whose provider-normalization model informed our routing. |
Context & token compression — engines
| Project | How it inspired OmniRoute | |
|---|---|---|
| Caveman · JuliusBrussee | 74.5k | The viral "why use many token when few token do trick" project — its caveman-speak philosophy powers our standard compression mode and 30+ fi |